I feel like the owners/operators of traditional websites like this one are now faced with the task of disallowing incoming requests from AI sources. I realize its nearly impossible to do, much like handling the traffic in a denial of service attack was years ago - not to mention that anyone can stand up a standalone LLM and such on their hobby machine. So I wish you luck.
I do rely on this site (forums and lost ski areas) often and appreciate the resource.
I am not sure how well the new terrain bodes for traditional websites when the AI result in google and such is the first thing that gets returned to people (especially younger people)
needawax wrote:
I feel like the owners/operators of traditional websites like this one are now faced with the task of disallowing incoming requests from AI sources. I realize its nearly impossible to do, much like handling the traffic in a denial of service attack was years ago - not to mention that anyone can stand up a standalone LLM and such on their hobby machine. So I wish you luck.
I do rely on this site (forums and lost ski areas) often and appreciate the resource.
I am not sure how well the new terrain bodes for traditional websites when the AI result in google and such is the first thing that gets returned to people (especially younger people)
It's a challenge for sure. I've spent some time trying to figure out how to block AI requests, but unfortunately, as you note, it's virtually impossible to block the ill-behaved ones as they're implemented as botnets and designed to elude such measures.
Here's an example of my page views over the past 18 months:
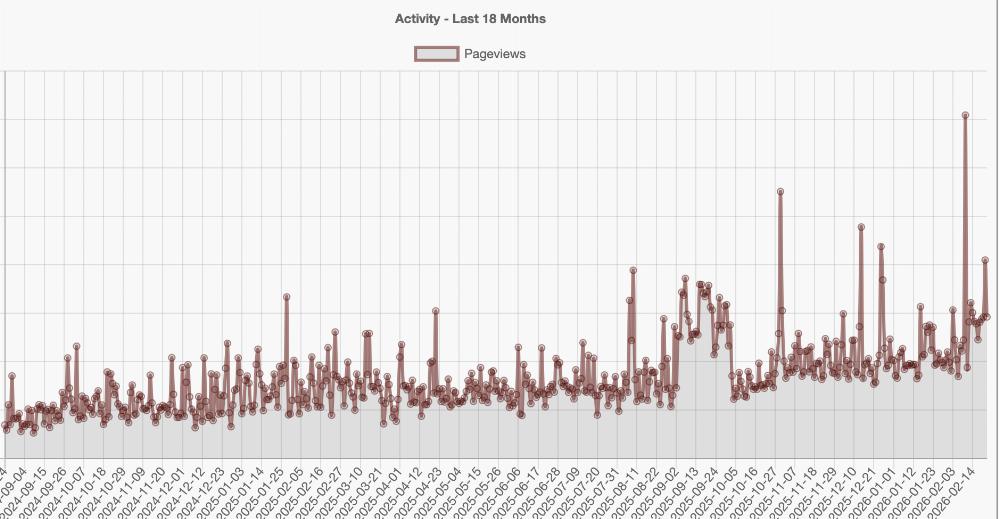
This would normally look like a very healthy graph, with a rapidly growing audience. But a lot of that growth (and certainly the "spikes" you see - some exceeding 100,000 page view requests per day) are simply AI bots scraping every character of text off every page.
And here is the unique visitors per day graph, which is even more dramatic:
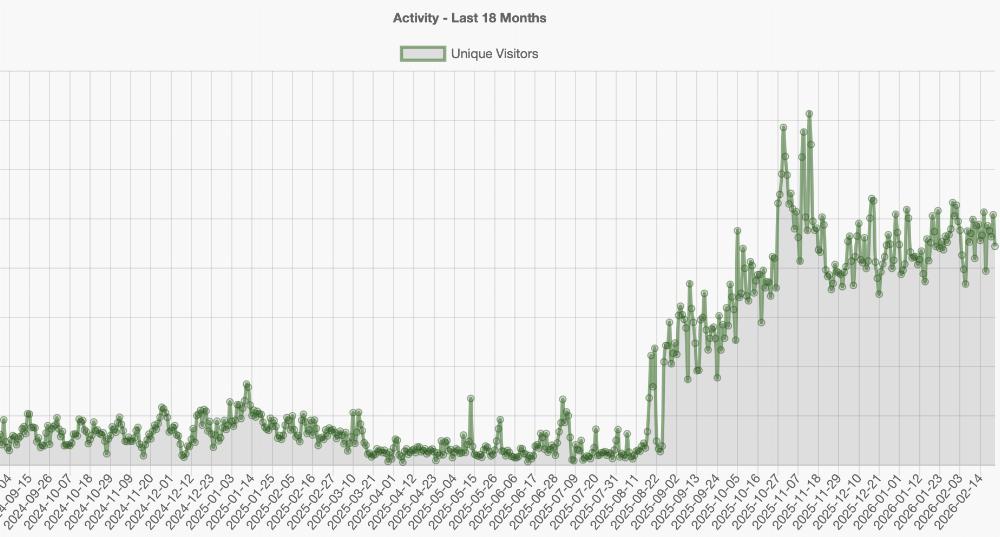 I mean, that's just crazy. Despite that sudden and continuous surge, I've seen traditional advertising revenue (e.g., from Google AdSense) go down, because AI bots don't view ads.
I mean, that's just crazy. Despite that sudden and continuous surge, I've seen traditional advertising revenue (e.g., from Google AdSense) go down, because AI bots don't view ads.
It is possible to tell AI bots not to scrape the site, but they ignore that request. A majority of the "firehose" requests I'm seeing are actually coming from distributed I.P. addresses in China.
This isn't the first challenge smaller, independent web sites have faced over the years, of course.
As you note, Google is trying to provide AI-produced "answers" right at the top of search results, so users never end up clicking on to other web sites. (This is the "no click" problem publishers are fretting about right now.)
But ultimately, it will be a problem if/when independent sites and human journalists disappear. Because AI can only provide answers for what it's trained on. Some of those answers might be "evergreen" (how many ounces are in a gallon?), but for anything that's evolving and changing, they need to keep scraping and training on new data. If there's no motivation for humans to produce that new data, AI results will become stale and outdated and incomplete.
It does seem like a "patron" type model is increasingly becoming the solution for sites like DCSki continue on. And I really appreciate any contributions users can make.
We don't want human reviewers, journalists, and people making comments to disappear. I've made a donation, and thanks for all the work over the years.
I'm in too.
This is a nice forum with good
Information and opinions.
Whew! It's difficult to get my head around the implications of AI. Your description of the current and potential future impacts of AI scraping is ominous.
Happy to contribute again to the continued operation of DCSki. com. This is a well-run website with a vigilant, talented editor and a supportive group of members. It has truly shaped my skiing since I returned to the slopes 23 years ago.
With appreciation, Woody
(PS I paid via Venmo, which didn't provide a way for me to include my forum name: bousquet19)
snowsmith wrote:
I have a lot of pop ups. Can I get some relief with a contribution. And thank you for this site!
You can get total relief! Thanks for your donation snowsmith - I sent you an e-mail with instructions on how to set the ad preference level.
This would normally look like a very healthy graph, with a rapidly growing audience. But a lot of that growth (and certainly the "spikes" you see - some exceeding 100,000 page view requests per day) are simply AI bots scraping every character of text off every page.
Out of curiosity, is this not what a captcha is meant to help with?
tkski wrote:
This would normally look like a very healthy graph, with a rapidly growing audience. But a lot of that growth (and certainly the "spikes" you see - some exceeding 100,000 page view requests per day) are simply AI bots scraping every character of text off every page.
Out of curiosity, is this not what a captcha is meant to help with?
Captcha's are generally placed at the point of registration (or other critical transactions like that, like making a financial transaction), and indeed I do use a captcha system when users first register for an account on DCSki. That, plus manually reviewing every registration request, is why you've basically never seen spam making its way to the DCSki Forums in over 30 years. (Interestingly, some of the AI bots have gotten *really* smart at trying to sneak past the Captcha system - it's spooky how good they've gotten. Thankfully I have a multi-layer system in place.)
But in terms of accessing general web pages on DCSki (reading vs. posting), it's not practical to have a Captcha system, and to be honest, with modern AI automated Captcha systems are essentially ineffective. You would get very annoyed if you had to solve a puzzle on every single page you visit! And I don't want to require users to register to view pages on DCSki; most visitors to DCSki are "lurkers." There are tens of thousands of unique pages on DCSki, and you want to make them easily accessible to both users and (legitimate) search engines. There is a protocol in place that honest search engines like Google follow (for example, I can direct them to not index certain pages, or not to index more than X pages per day, or even to discontinue indexing entirely), but that's always been based on the trust system, and all these AI companies (especially the ones from other countries) don't have any interest in being honest or courteous in their scraping and copyright infringement.
In the past, I might see a single I.P. address misbehaving (such as downloading hundreds of pages from DCSki per second) and I could block it. But a lot of these systems are using botnets with hundreds or thousands of unique I.P. addresses, randomly bouncing between them, so it's like trying to swat a thousand flies at once.
It's such a cat and mouse game.
A lot of the bots are scrapers in my experience from an org I should don't want to name b/c of Russia, China, Iran and Iraq. I found AWS WAF and Shield to be pretty good especially against DDOS and you can mod the rules to tailor like XXS and submit payloads. BUT you have to fork over eventually. If it isn't a hassle just keep a low profile. I noticed URLs are following sort of REST format I had to clean that up for another org I can;t named I just did light AES with a shared key in front that seemed to work well and got past all the pen test flags.
Or meh NM if it works for you.
's are generally placed at the point of registration (or other critical transactions like that, like making a financial transaction), and indeed I do use a captcha system when users first register for an account on DCSki. That, plus manually reviewing every registration request, is why you've basically never seen spam making its way to the DCSki Forums in over 30 years. (Interestingly, some of the AI bots have gotten *really* smart at trying to sneak past the Captcha system - it's spooky how good they've gotten. Thankfully I have a multi-layer system in place.)
But in terms of accessing general web pages on DCSki (reading vs. posting), it's not practical to have a Captcha system, and to be honest, with modern AI automated Captcha systems are essentially ineffective. You would get very annoyed if you had to solve a puzzle on every single page you visit! And I don't want to require users to register to view pages on DCSki; most visitors to DCSki are "lurkers." There are tens of thousands of unique pages on DCSki, and you want to make them easily accessible to both users and (legitimate) search engines. There is a protocol in place that honest search engines like Google follow (for example, I can direct them to not index certain pages, or not to index more than X pages per day, or even to discontinue indexing entirely), but that's always been based on the trust system, and all these AI companies (especially the ones from other countries) don't have any interest in being honest or courteous in their scraping and copyright infringement.
In the past, I might see a single I.P. address misbehaving (such as downloading hundreds of pages from DCSki per second) and I could block it. But a lot of these systems are using botnets with hundreds or thousands of unique I.P. addresses, randomly bouncing between them, so it's like trying to swat a thousand flies at once.
It's such a cat and mouse game.
"Cat and mouse" sums it up pretty accurately. But then, that's always been the case. I don't know what my strategy would be if I ran a forum, or an informational site like this one today. I'd probably move to subscription only (this site has a lot of gems in it and not just a bunch of regurgitated cruft, certainly worthy of the small fee). Much of IT is waste, spending money and playing to silly rules that have evolved over the years only to preserve IT and related services. That used to interest me, but now not so much. (e.g., you can construct a pretty sophisticated DDoS attack that appears to your paid protective services and filters as legit traffic) It's an interesting problem to try (and pay) to solve, but in the end this is a pretty nice site and keeping that spirit is the main idea.
I'm sure most of the legit traffic here is in fact lurkers -- people who have accounts here, read the forums, and never post. Or people who have no account and just tune in to the Mid atlantic scene.
Temu ads or no temu ads, I personally ignored all ads completely even as a non-supporter. I'm glad to have the option to disable them as a supporter. Maybe look at the portion of non-account, non-contributor visits that actually convert ad wise.
TheCrush wrote:
A lot of the bots are scrapers in my experience from an org I should don't want to name b/c of Russia, China, Iran and Iraq. I found AWS WAF and Shield to be pretty good especially against DDOS and you can mod the rules to tailor like XXS and submit payloads. BUT you have to fork over eventually. If it isn't a hassle just keep a low profile. I noticed URLs are following sort of REST format I had to clean that up for another org I can;t named I just did light AES with a shared key in front that seemed to work well and got past all the pen test flags.
Or meh NM if it works for you.
's are generally placed at the point of registration (or other critical transactions like that, like making a financial transaction), and indeed I do use a captcha system when users first register for an account on DCSki. That, plus manually reviewing every registration request, is why you've basically never seen spam making its way to the DCSki Forums in over 30 years. (Interestingly, some of the AI bots have gotten *really* smart at trying to sneak past the Captcha system - it's spooky how good they've gotten. Thankfully I have a multi-layer system in place.)
But in terms of accessing general web pages on DCSki (reading vs. posting), it's not practical to have a Captcha system, and to be honest, with modern AI automated Captcha systems are essentially ineffective. You would get very annoyed if you had to solve a puzzle on every single page you visit! And I don't want to require users to register to view pages on DCSki; most visitors to DCSki are "lurkers." There are tens of thousands of unique pages on DCSki, and you want to make them easily accessible to both users and (legitimate) search engines. There is a protocol in place that honest search engines like Google follow (for example, I can direct them to not index certain pages, or not to index more than X pages per day, or even to discontinue indexing entirely), but that's always been based on the trust system, and all these AI companies (especially the ones from other countries) don't have any interest in being honest or courteous in their scraping and copyright infringement.
In the past, I might see a single I.P. address misbehaving (such as downloading hundreds of pages from DCSki per second) and I could block it. But a lot of these systems are using botnets with hundreds or thousands of unique I.P. addresses, randomly bouncing between them, so it's like trying to swat a thousand flies at once.
It's such a cat and mouse game.







